
其实很人都以为Python才可以做爬虫,其实C++与Java照样也是可以的,因为爬虫的原理很简单,无非就是分析HTTP(s)请求,然后通过代码模拟浏览器去发起请求,对于发起网络请求框架的我选择的是Apache的OKHttp,毕竟自己手动拼接HTTP请求体还是工作量比较大的一个事情。拿到网页后就需要解析网页关键内容,此时Jsoup就发挥作用了,通过节点选择器 + 表达式可以很方便的拿到想要的数据,在我的开源项目中可以看到这个爬取过程的核心实现,https://gitee.com/zouchanglin/spider_xpu
HttpClient
1 | <dependency> |
Jsoup
我们抓取到页面之后,还需要对页而进行解析。可以使用字符串处理工具解析页面,也可以使用正则表达式,但是这些方法都会带来很大的开发成本,所以我们需要使用一款专门解析HTML页面的技术。
jsoup介绍
Jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文木内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup的主要功能
1.从一个URL,文件或字符串中解析HTML;
2.使用DOM或CSS选择器来查找、取出数据;
3.可操作HTML元素、属性、文本;
Jsoup实战
1 | <dependencies> |
1 |
|
虽然使用Jsoup可以替代HttpClient直接发起请求解析数据,但是往往不会这样用,因为实际的开发过程中,需要使用到多线程,连接池,代理等等方式,而Jsoup对这些的支持并不是很好,所以我们一般把Jsoup仅仅作为Html
解析工具使用。
Dom方式遍历文档
元素获取
1、根据id查询元素getElementByld
2、根据标签获取元素getElementsByTag
3、根据class获取元素getElementsByClass
4、根据属性获取元素getElementsByAttribute
元素中获取数据
1、从元素中获取id
2、从元素中获取className
3、从元素中获取属性的值 attr
4、从元素中获取所有属性attributes
5、从元素中获取文本内容text
Selector选择器
tagname:通过标签查找元素,比如: span#id:通过ID查找元素,比如: #city_bj.class:通过class名称查找元素,比如: .class_a
[attribute]:利用属性查找元素,比如:[abc]
[attr=value]:利用属性值来查找元素,比如: [class=s_name]
Selector选择器组合使用
el#id:元素+ID,比如:h3#3city_bjel.class:元素+class,比如:li.class_ael[attr]:元素+属性名,比如:span[abc]
任意组合:比如: span[abc].s_nameancestor child:查找某个元素下子元素,比如: .city_con li查找city_con下的所有liparent > child:查找某个父元素下的直接子元素,比如:.city_con > ul > li查找city_con第一级(直接子元素)的ul,再找所有ul下的第一级liparent > *:查找某个父元素下所有直接子元素
1 | package jsoup; |
正方教务爬虫
1、引入依赖
1 | <dependencies> |
2、使用示例
1 | import cn.zouchanglin.spider_xpu.SpiderResult; |
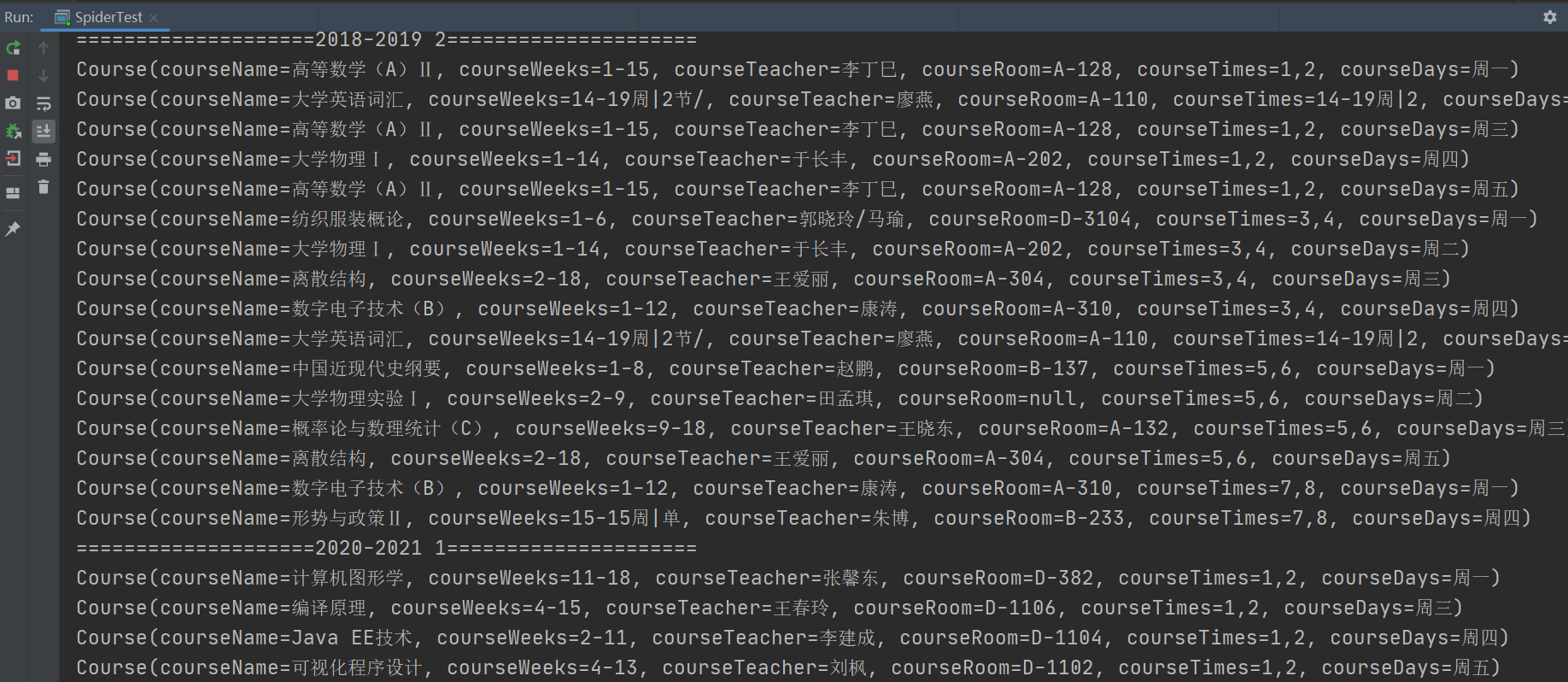
通过对学生信息和学生所有课表的爬取,效果还不错!


- 本文作者: Tim
- 本文链接: https://zouchanglin.cn/2020/08/19/628369017.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 许可协议。转载请注明出处!